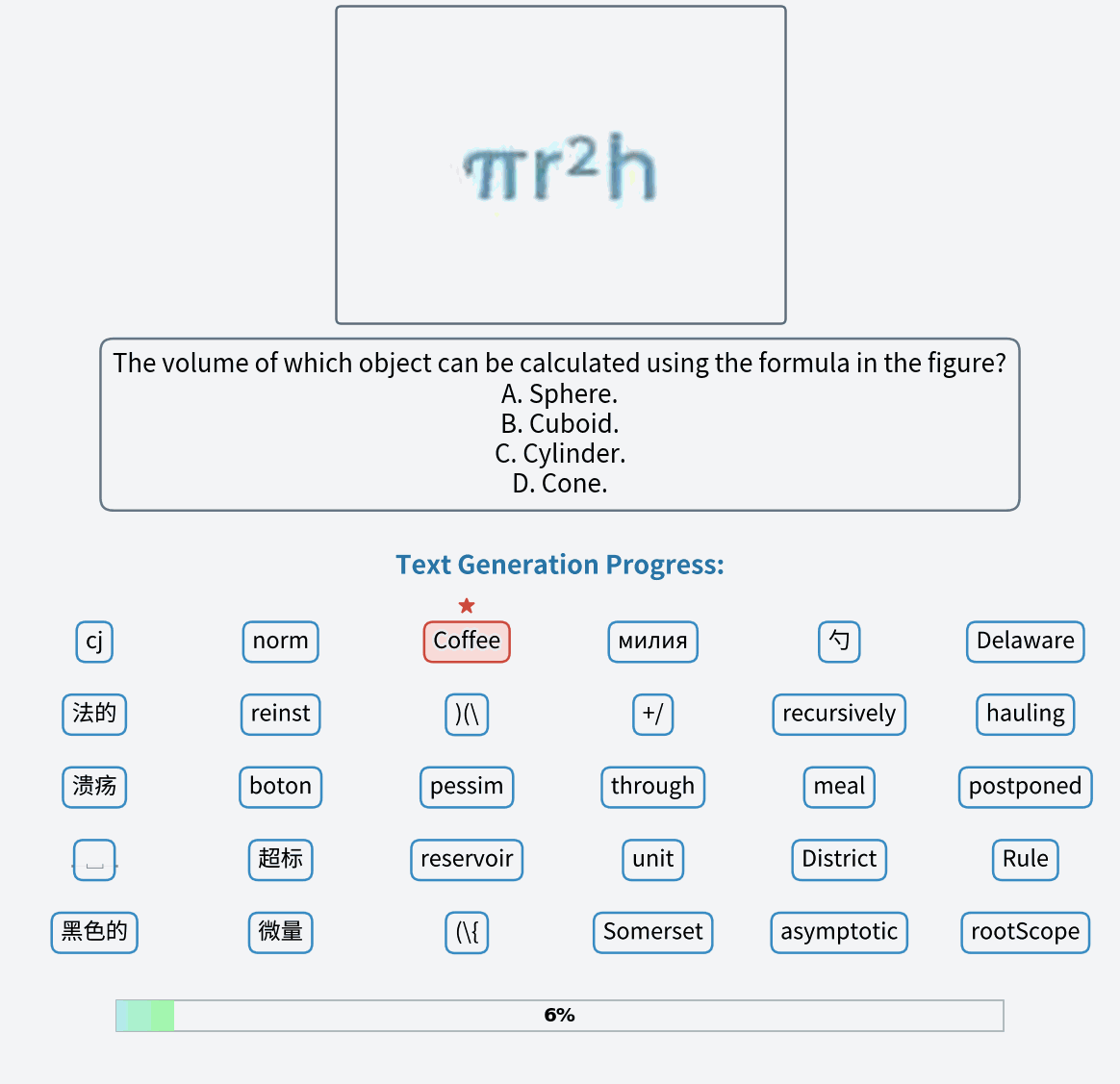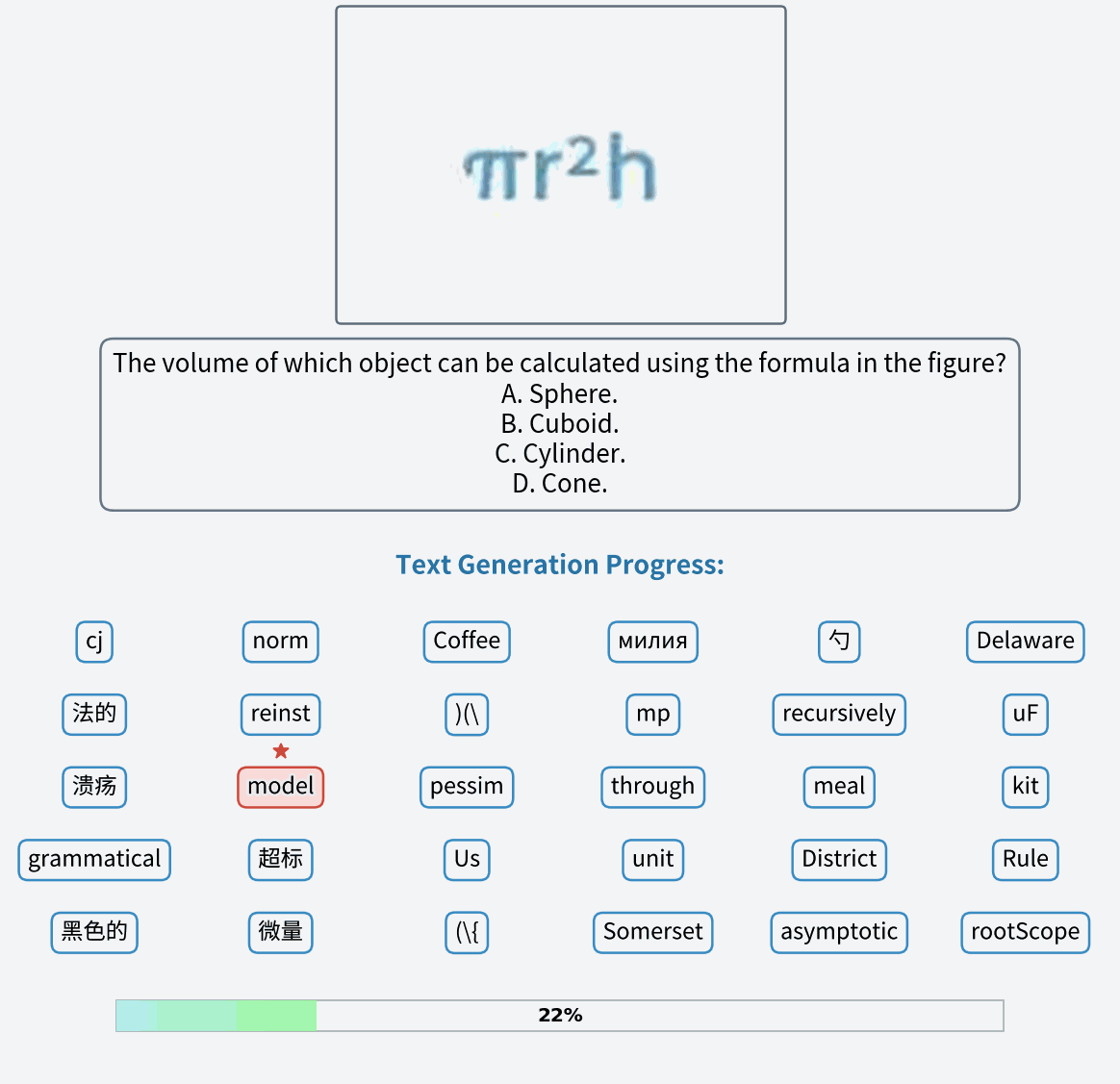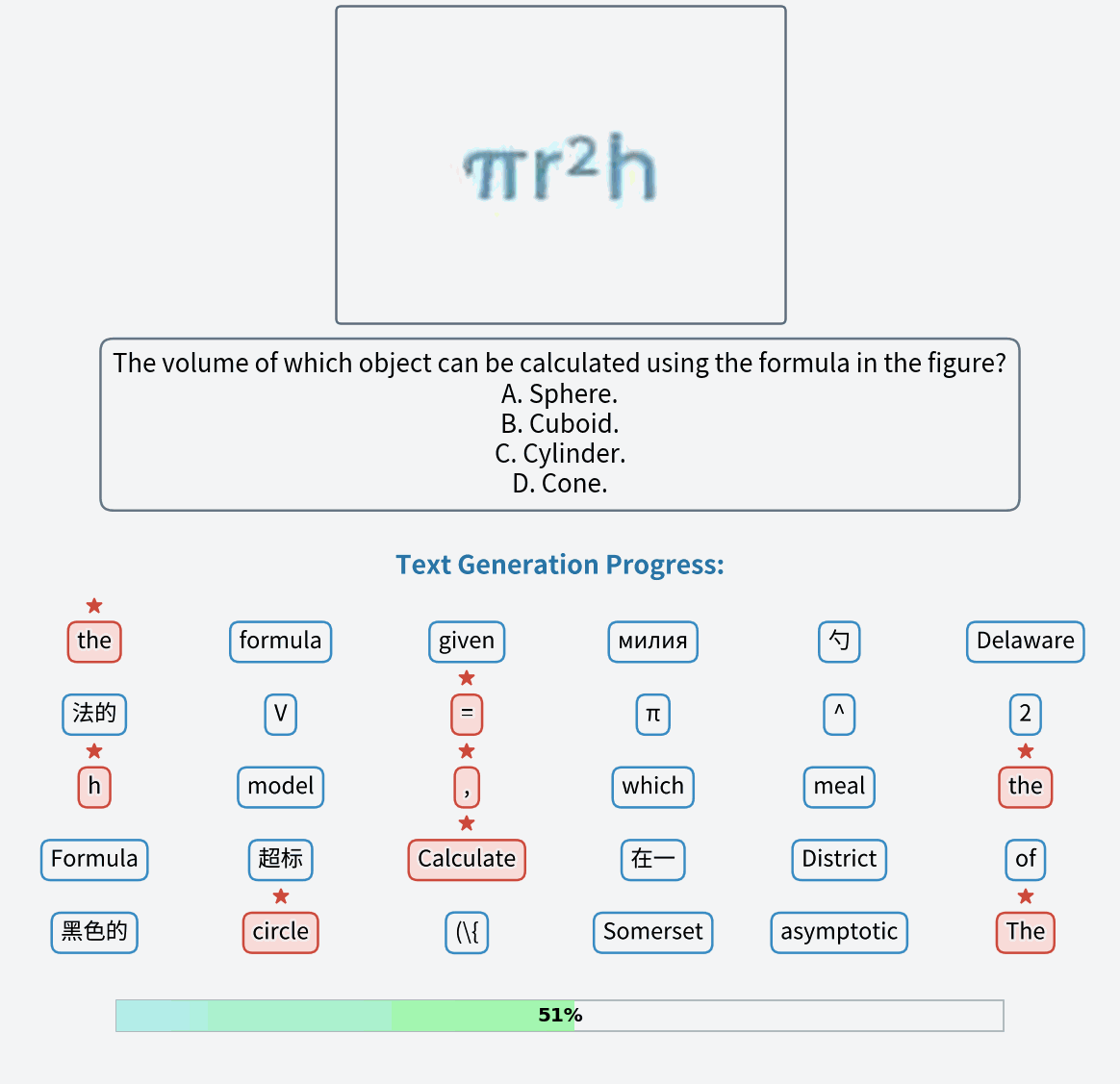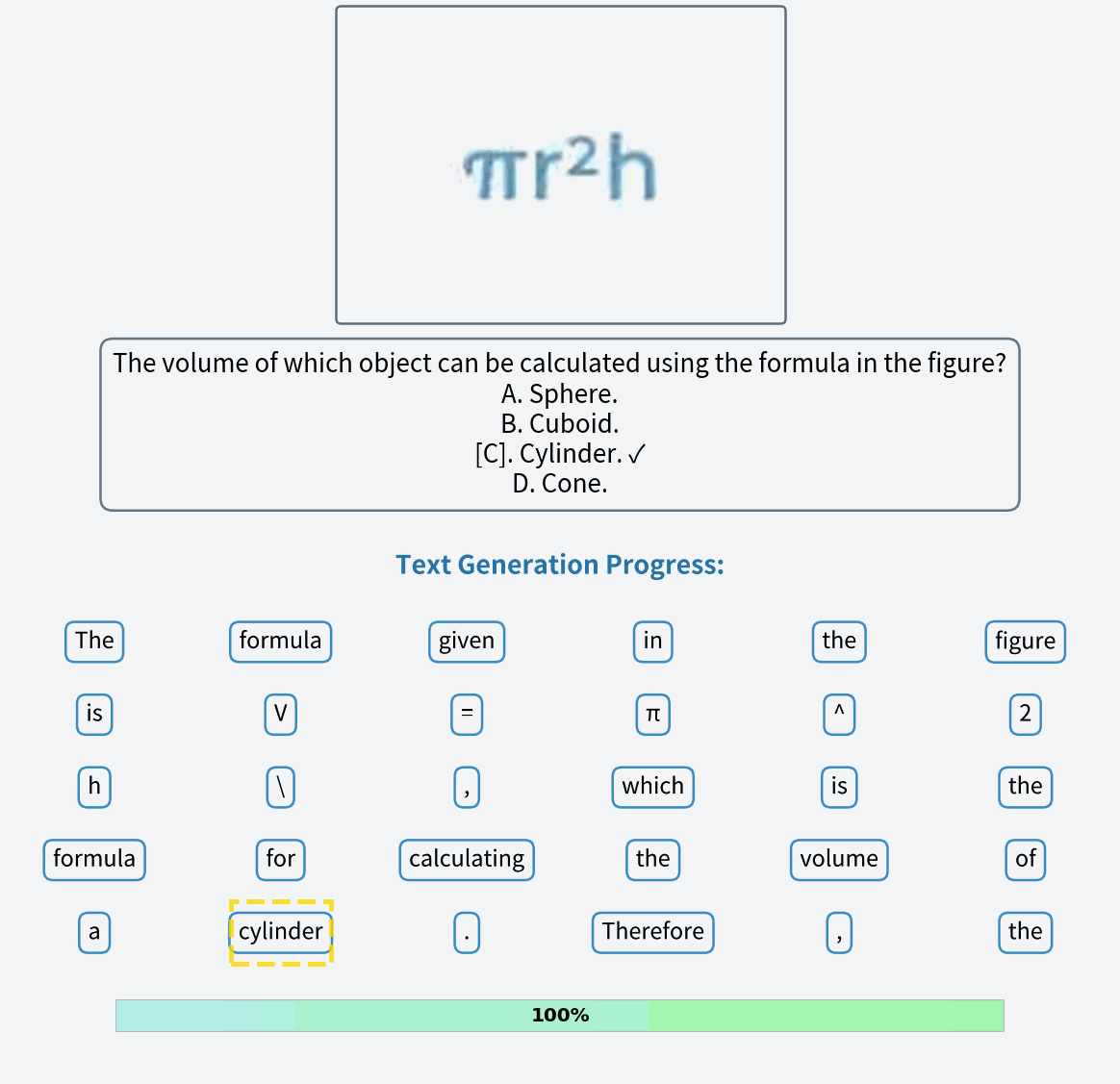
A red colored car.
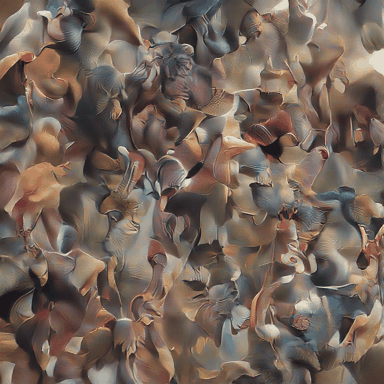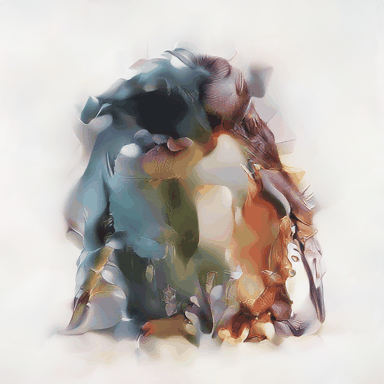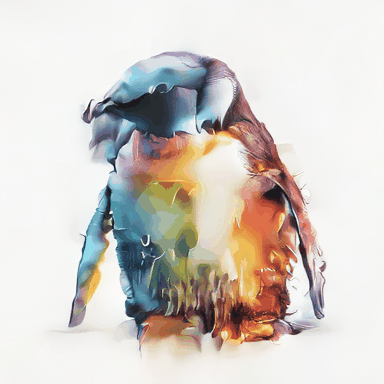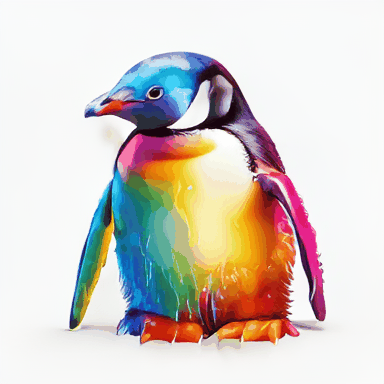
Rainbow coloured penguin.
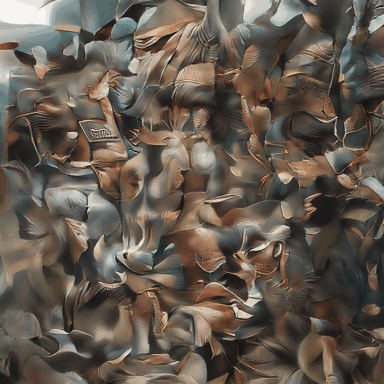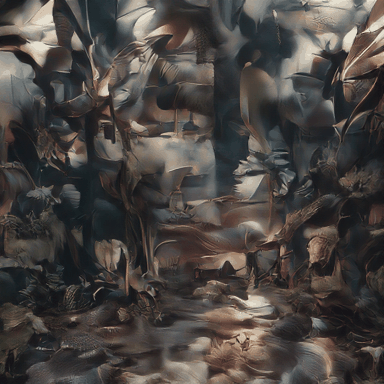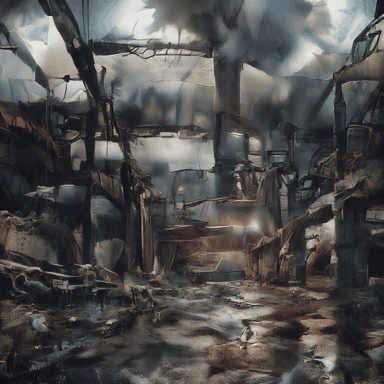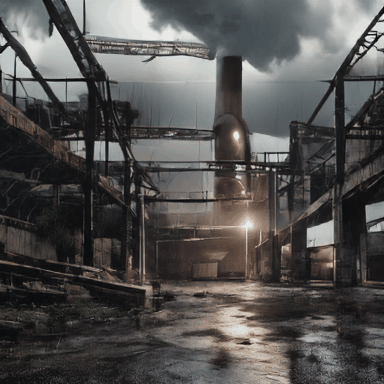
Hyper-realistic photo of an abandoned industrial site during a storm.
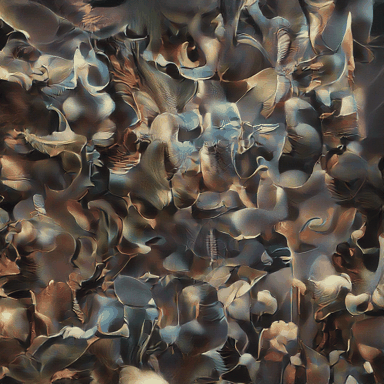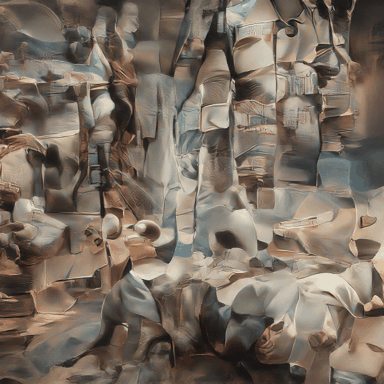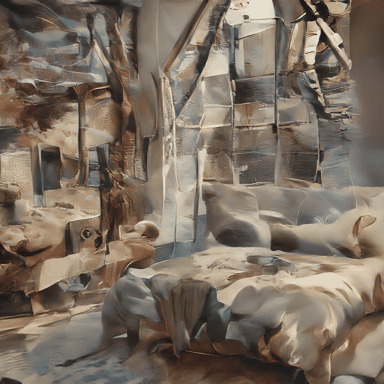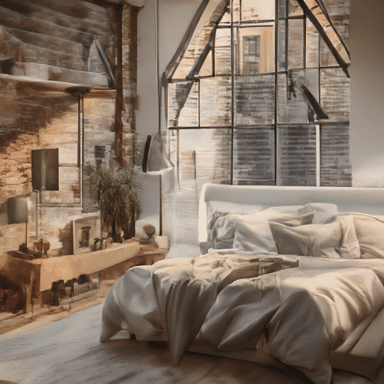
A loft bedroom with a white bed next to the bedside table
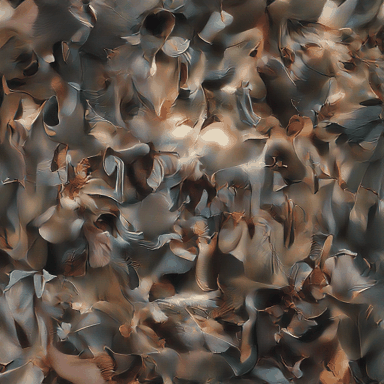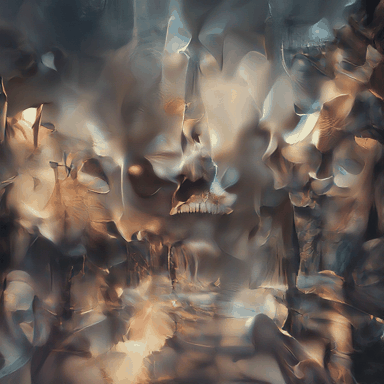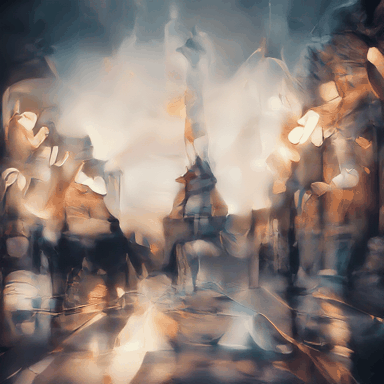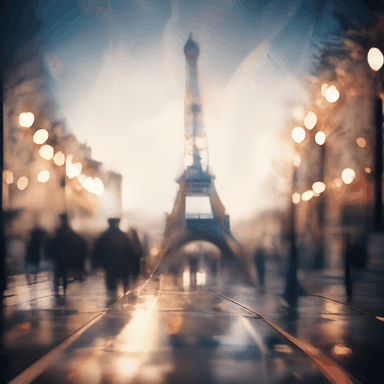
Eiffel Tower, large aperture, blurred background
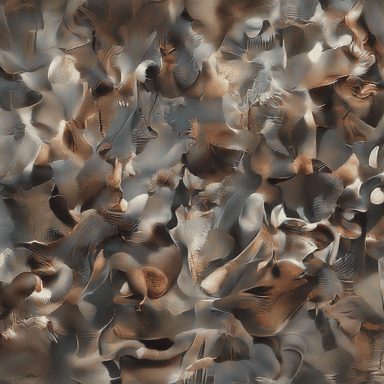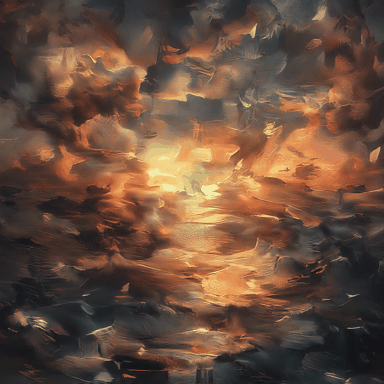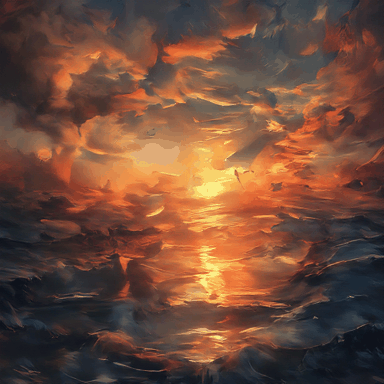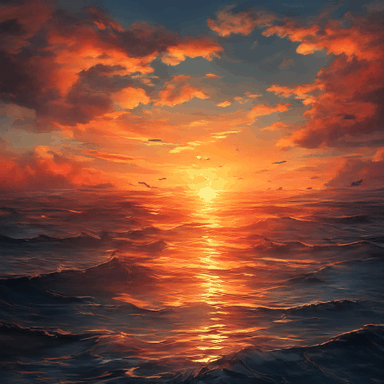
The sunset is at the end of the sky and the sea.
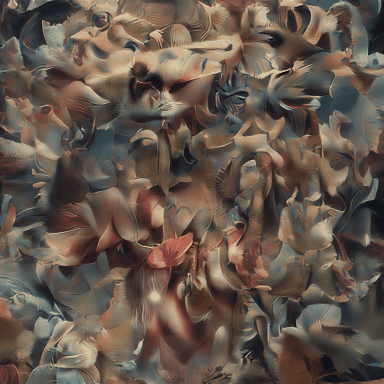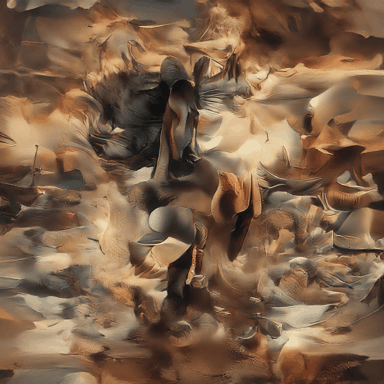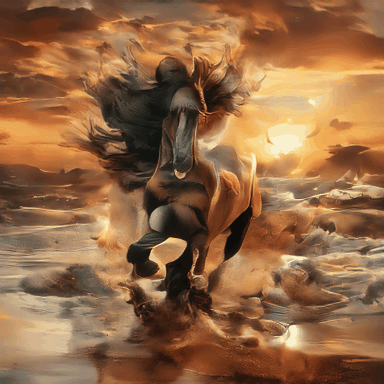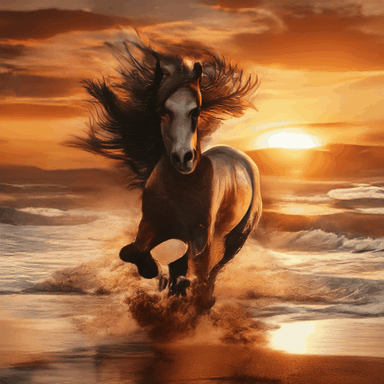
A horse running on the beach at sunrise
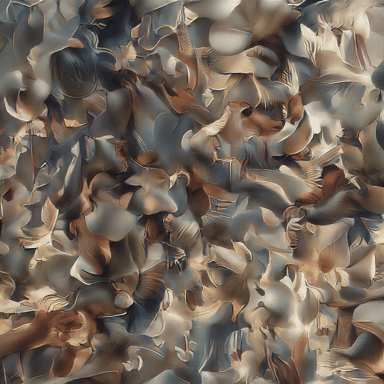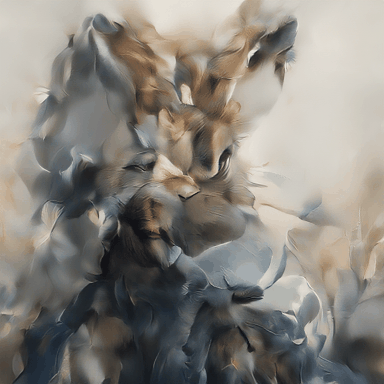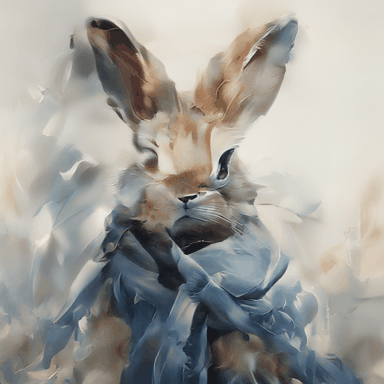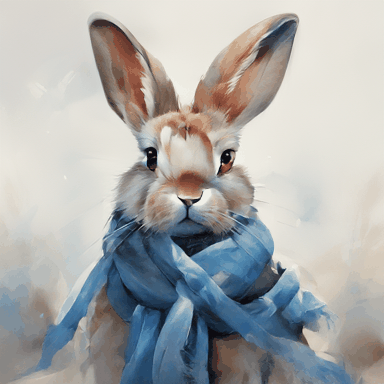
A rabbit wears a blue scarf.
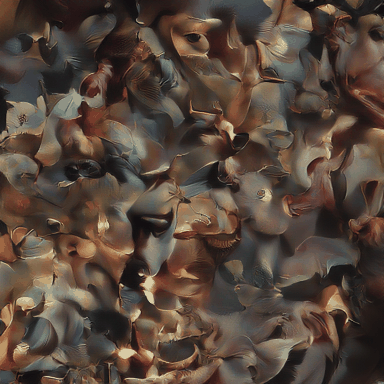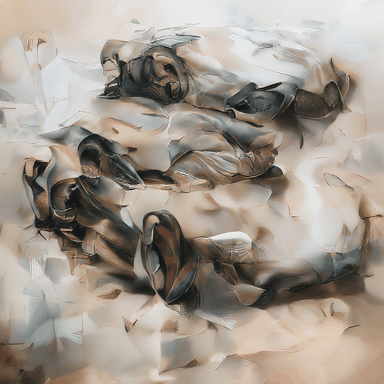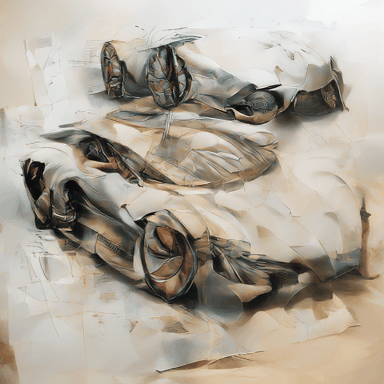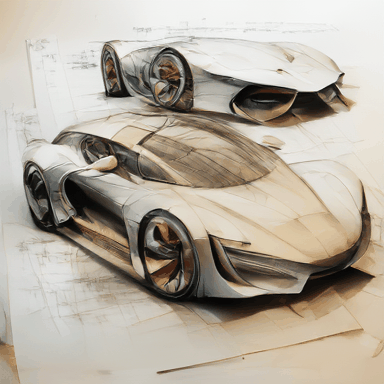
Automobile design drawings, sketch